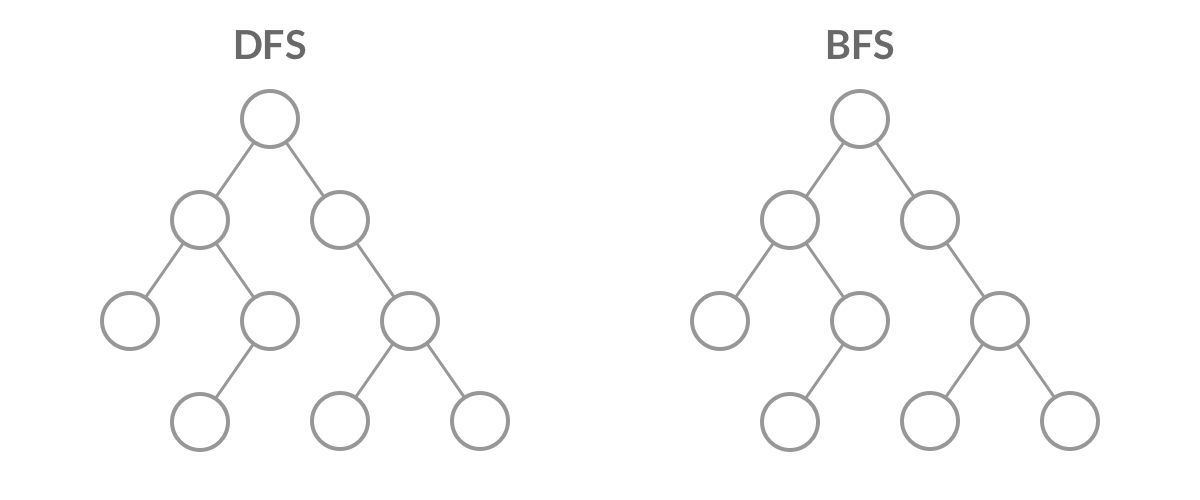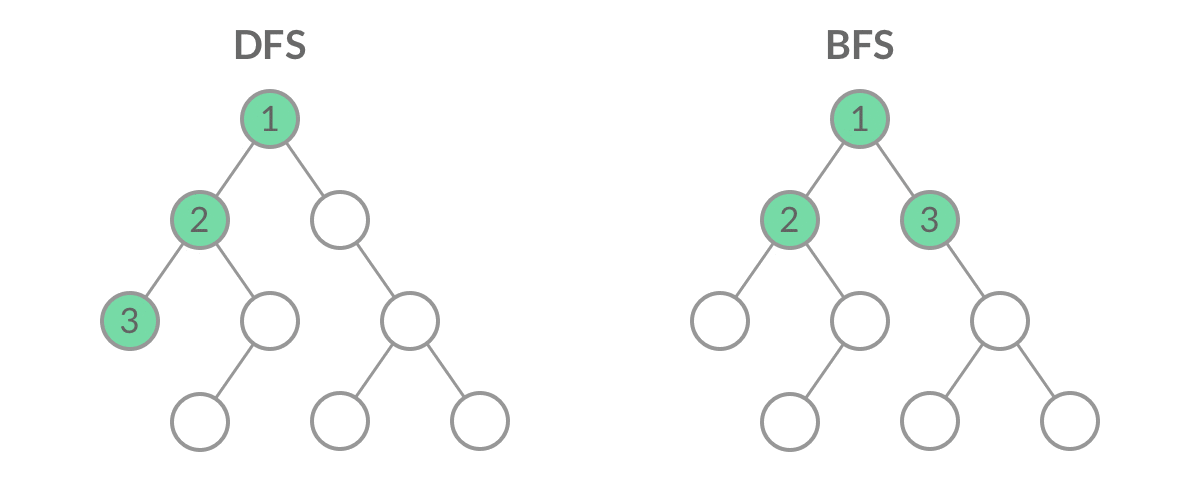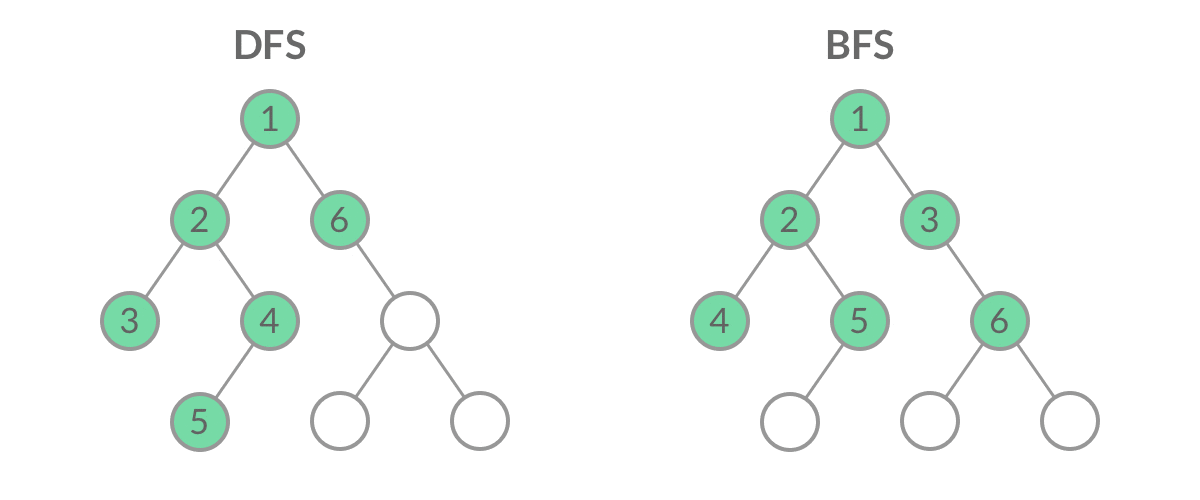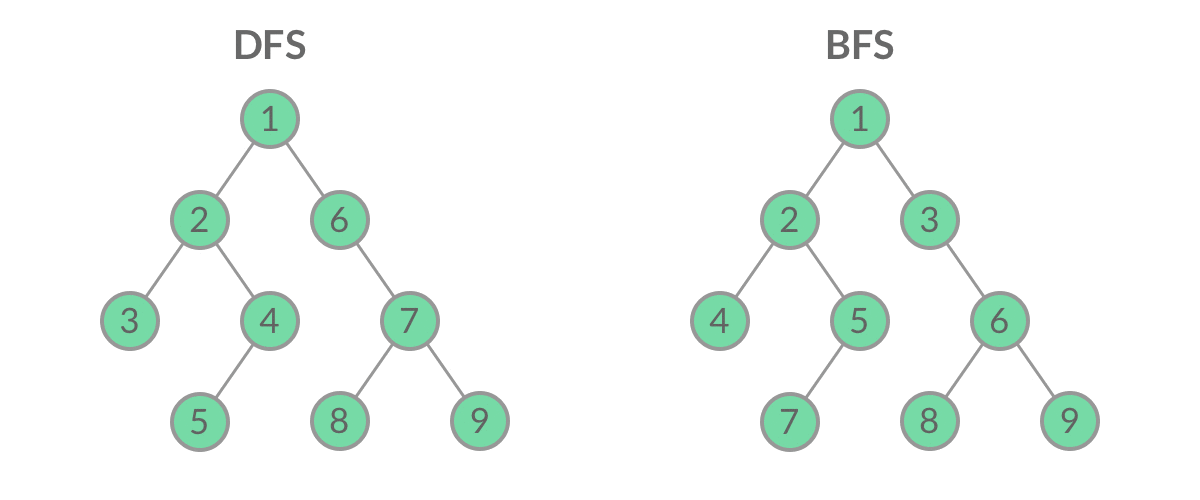
深度优先遍历(Depth First Search, 简称DFS)与广度优先遍历(Breath First Search,简称BFS)是图论中两种非常重要的算法,生产上广泛用于拓扑排序,寻路(走迷宫)、搜索引擎、爬虫等。
DFS (Deep First Search) DFS:从当前节点开始,先标记当前节点,再寻找与当前节点相邻,且未标记过的节点( 这是一个递归思想的DFS)
当前节点不存在下一个节点,则返回前一个节点进行DFS
当前节点存在下一个节点,则从下一个节点进行DFS
DFS 遍历使用递归遍历:
1 2 3 4 5 6 7 void dfs (TreeNode root) if (root == null ){ return ; } dfs(root.left); dfs(root.right); }
只是比较两段代码的话,最直观的感受就是:DFS 遍历的代码比 BFS 简洁太多了!这是因为递归的方式隐含地使用了系统的 栈,我们不需要自己维护一个数据结构。如果只是简单地将二叉树遍历一遍,那么 DFS 显然是更方便的选择。
网格结构中的 DFS 网格问题的基本概念
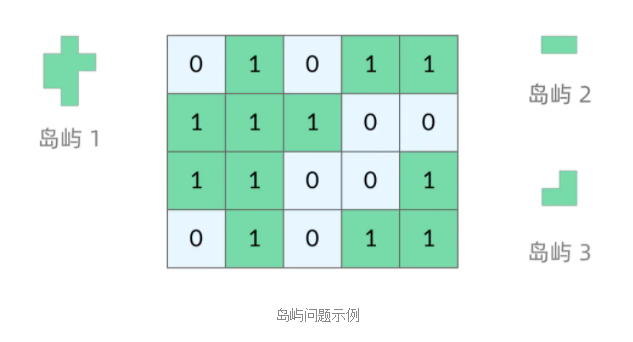
我们首先明确一下岛屿问题中的网格结构是如何定义的,以方便我们后面的讨论。
网格问题是由 个小方格组成一个网格,每个小方格与其上下左右四个方格认为是相邻的,要在这样的网格上进行某种搜索。
岛屿问题是一类典型的网格问题。每个格子中的数字可能是 0 或者 1。我们把数字为 0 的格子看成海洋格子,数字为 1 的格子看成陆地格子,这样相邻的陆地格子就连接成一个岛屿。
在这样一个设定下,就出现了各种岛屿问题的变种,包括岛屿的数量、面积、周长等。不过这些问题,基本都可以用 DFS 遍历来解决。
DFS 的基本结构
网格结构要比二叉树结构稍微复杂一些,它其实是一种简化版的图 结构。要写好网格上的 DFS 遍历,我们首先要理解二叉树上的 DFS 遍历方法,再类比写出网格结构上的 DFS 遍历。我们写的二叉树 DFS 遍历一般是这样的:
1 2 3 4 5 6 7 8 9 void travese (TreeNode root) if (root == null ){ return ; } travese(root.left); travese(root.right); }
可以看到,二叉树的DFS有两个要素:【访问相邻节点 】 和 【判断base case 】。
第一个要素是访问相邻的节点 。二叉树的相邻节点非常简单,只有左子树和右子树。二叉树本身就是一个递归定义的结构:一颗二叉树,他的左子树和右子树也是一颗二叉树。那么我们的DFS遍历只需要调用左子树和右子树即可。
第二个要素就是判断base case 。一般来说,二叉树遍历的base case是 root == null。这样一个条件判断其实有两个含义:
表示root指向指向的子树为空,不需要再往下遍历了。
在root == null的时候及时返回,可以让后面的root.left 和root.right操作不会出现空指针异常
对于网格上的DFS,可以参考二叉树的DFS,写出网格的DFS的两个要素:
相邻节点对于格子 (r, c) 来说(r 和 c 分别代表行坐标和列坐标),四个相邻的格子分别是 (r-1, c)、(r+1, c)、(r, c-1)、(r, c+1)。换句话说,网格结构是「四叉」的。
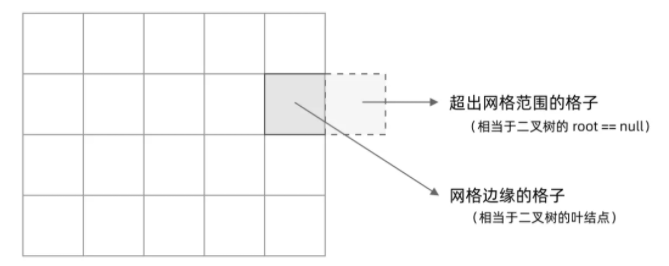
其次,网格 DFS 中的 base case 是什么?从二叉树的 base case 对应过来,应该是网格中不需要继续遍历、grid[r][c] 会出现数组下标越界异常的格子,也就是那些超出网格范围的格子。
DFS遍历网格的框架代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void dfs (int [][],grid int r, int c) if (!inArea(grid, r, c)){ return ; } if (grid[r][c] != 1 ){ return ; } grid[r][c] = 2 ; dfs(grid, r - 1 , c); dfs(grid, r + 1 , c); dfs(grid, r, c - 1 ); dfs(grid, r, c + 1 ); } boolean inArea (int [][] grid, int r, int c) return <= r && r < grid.length && 0 <= c && c < grid[0 ].length; }
岛屿问题解决 这道题目只需要对每个岛屿做 DFS 遍历,求出每个岛屿的面积就可以了。求岛屿面积的方法也很简单,代码如下,每遍历到一个格子,就把面积加一。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public int maxAreaOfIsland (int [][] grid) int res = 0 ; for (int i = 0 ; i < grid.length; ++i){ for (int j = 0 ; j < grid[0 ].length; ++j){ int a = area(grid, r , c); res = Math.max(res, a); } } } int area (int [][] grid, int r, int c) if inArea (grid, r ,c) return 0 ; } if (grid[r][c] != 1 ){ return 0 ; } grid[r][c] == 2 ; return 1 + are(grid, r - 1 , c) + are(grid, r + 1 , c) + are(grid, r, c - 1 ) + are(grid, r, c + 1 ); } boolean inArea (int [][] grid, int r, int c) return 0 <= r && r <= grid.length && 0 <= c && c < grid[0 ].length; }
实话说,这道题用 DFS 来解并不是最优的方法。对于岛屿,直接用数学的方法求周长会更容易。不过这道题是一个很好的理解 DFS 遍历过程的例题,不信你跟着我往下看。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public int islandPerimter (int [][] grid, int r, int c) for (int r = 0 ; r < grid.length; r++){ for (int c = 0 ; c < grid[0 ].length; c++){ if (grid[r][c] == 1 ){ return dfs(grid, r, c); } } } return 0 ; } int dfs (int [][] grid, int r, int c) if (!inArea(grid, r, c)){ return 1 ; } if (grid[r][c] == 0 ){ return 1 ; } if (grid[r][c] != 1 ){ return 0 ; } grid[r][c] = 2 ; return dfs(grid, r - 1 , c) + dfs(grid, r + 1 , c) + dfs(grid, r, c - 1 ) + dfs(grid, r, c + 1 ); }
BFS(Breath First Search) BFS: 广度优先算法便如其名字,他是以广度为优先的,一层一层搜索下去,就像病毒感染,扩散性的传播下去。
比如每遍历start周围的一个“1”节点的时候,就把跟它相关联的“2”节点保存到队列中
然后依次访问队列内容,并对每个队列元素重复上个步骤
由此重复下去,直到队列为空或者搜索到终点
BFS 遍历使用队列数据结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 void bfs (TreeNode root) Queue<TreeNode> queue = new ArrayDeque<>(); queue.add(root); while (!queue.isEmpty()){ TreeNode node = queue.poll(); if (node.left != null ){ queue.add(node.left); } if (node.right != null ){ queue.add(node.right); } } }
BFS 的应用一:层序遍历 [102. 二叉树的层序遍历]
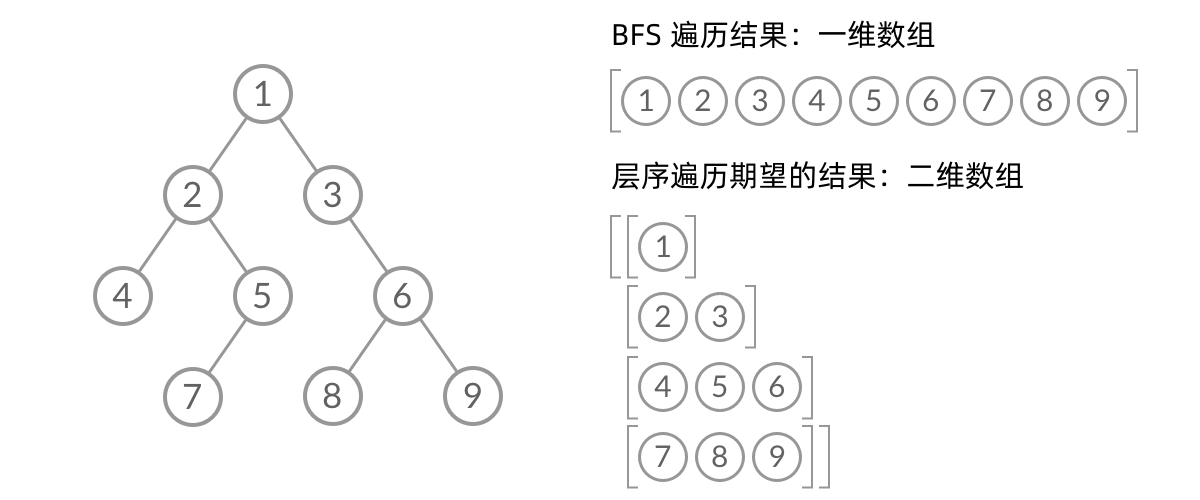
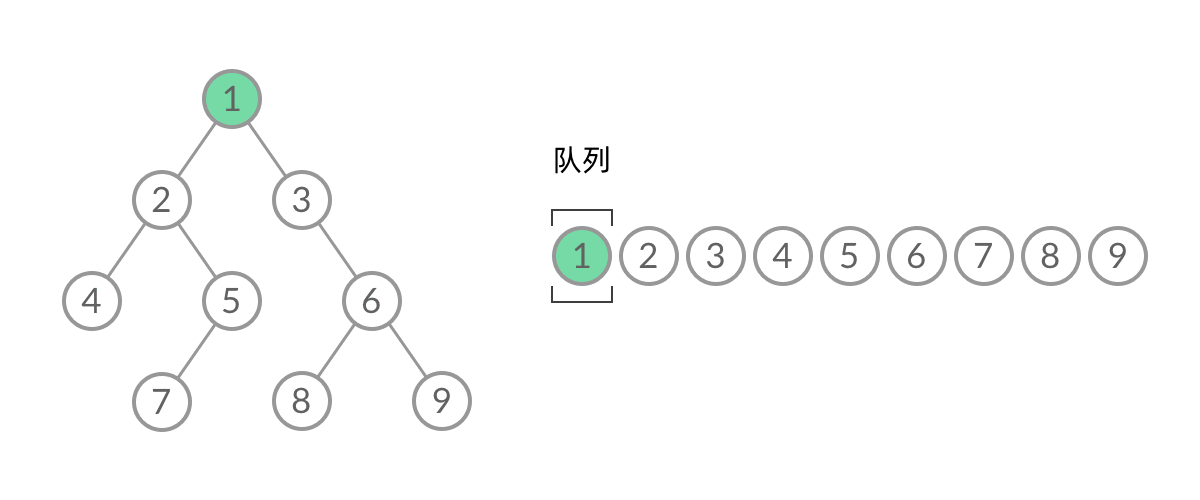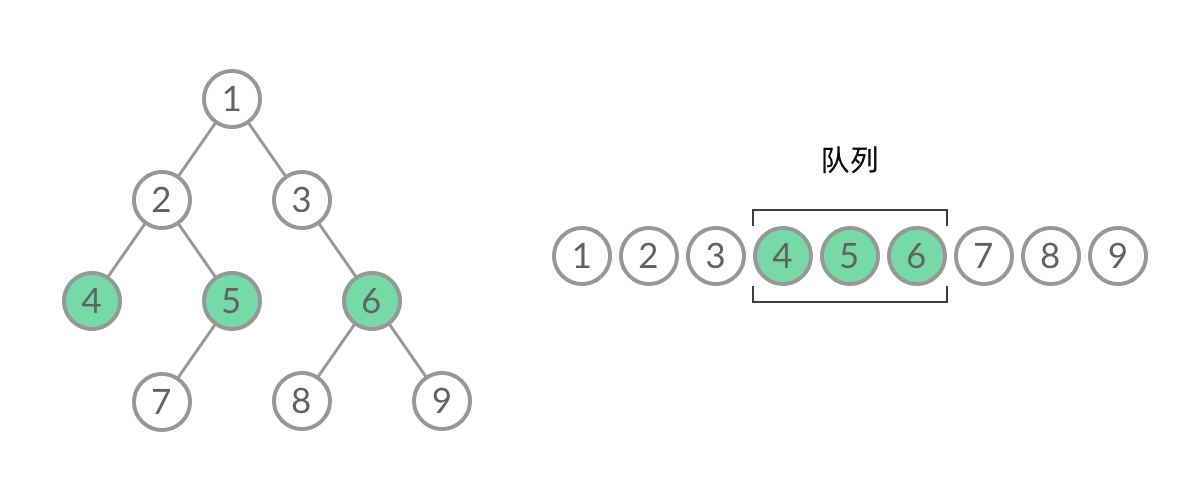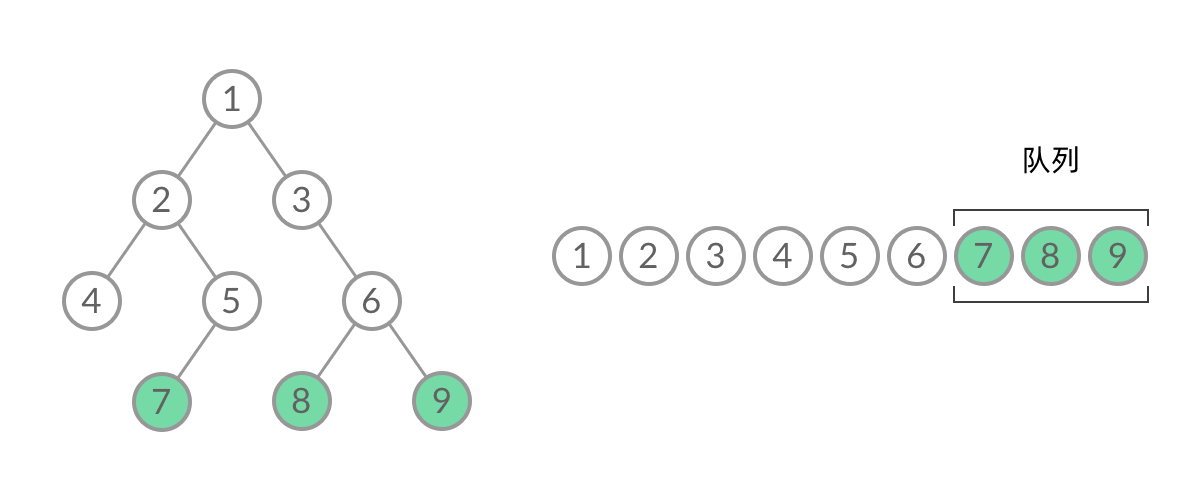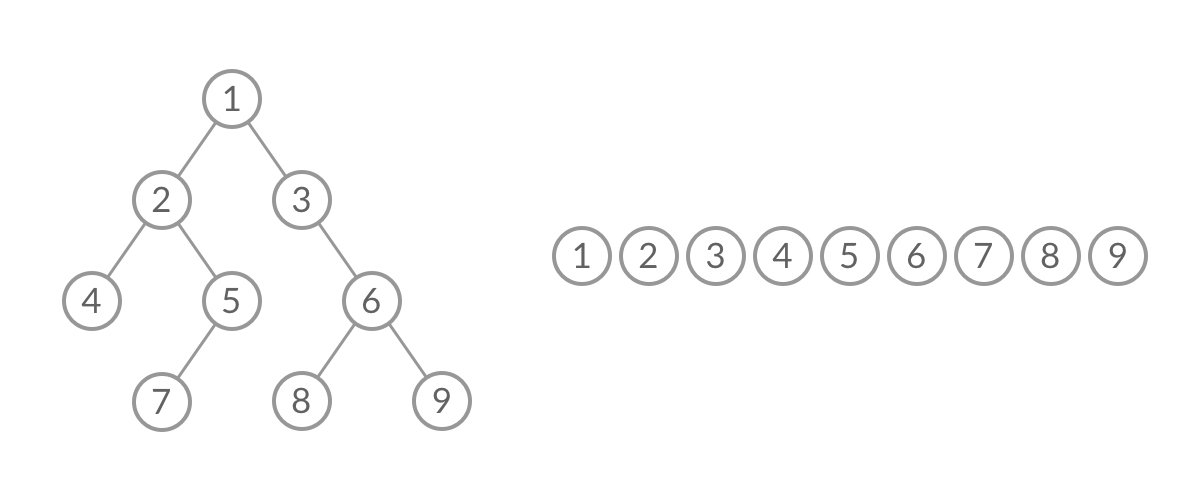
什么是层序遍历呢?简单来说,层序遍历就是把二叉树分层,然后每一层从左到右遍历:
乍一看来,这个遍历顺序和 BFS 是一样的,我们可以直接用 BFS 得出层序遍历结果。然而,层序遍历要求的输入结果和 BFS 是不同的。层序遍历要求我们区分每一层,也就是返回一个二维数组。而 BFS 的遍历结果是一个一维数组,无法区分每一层。
可以看到,此时队列中的结点是 3、4、5,分别来自第 1 层和第 2 层。这个时候,第 1 层的结点还没出完,第 2 层的结点就进来了,而且两层的结点在队列中紧挨在一起,我们无法区分队列中的结点来自哪一层。
因此,我们需要稍微修改一下代码,在每一层遍历开始前,先记录队列中的结点数量 nn(也就是这一层的结点数量),然后一口气处理完这一层的 nn 个结点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void bfs (TreeNode root) Queue<TreeNode> queue = new ArrayDeque<>(); queue.add(root); while (!queue.isEmpty()){ int n = queue.size(); for (int i = 0 ; i < n; ++i){ TreeNode node = queue.poll(); if (node.left == null ){ queue.add(node.left); } if (node.right == null ){ queue.add(node.right); } } } }
可以看到,在 while 循环的每一轮中,都是将当前层的所有结点出队列,再将下一层的所有结点入队列,这样就实现了层序遍历。
最终我们得到的题解代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public List<List<Integer>> levelOrder(TreeNode root){ List<List<Integer>> res = new ArrayList<>(); Queue<TreeNode> queue = new ArrayDeque<>(); if (root != null ){ queue.add(root); } while (!queue.isEmpty()){ int n = queue.size(); List<Integer> level = new ArrayList<>(); for (int i = 0 ; i < n; ++i){ TreeNode node = queue.poll(); level.add(node.val); if (node.left != null ){ queue.add(node.left); } if (node.right != null ){ queue.add(node.right); } } res.add(level); } return res; }
BFS 的应用二:最短路径 在一棵树中,一个结点到另一个结点的路径是唯一的,但在图中,结点之间可能有多条路径,其中哪条路最近呢?这一类问题称为最短路径问题。最短路径问题也是 BFS 的典型应用,而且其方法与层序遍历关系密切。
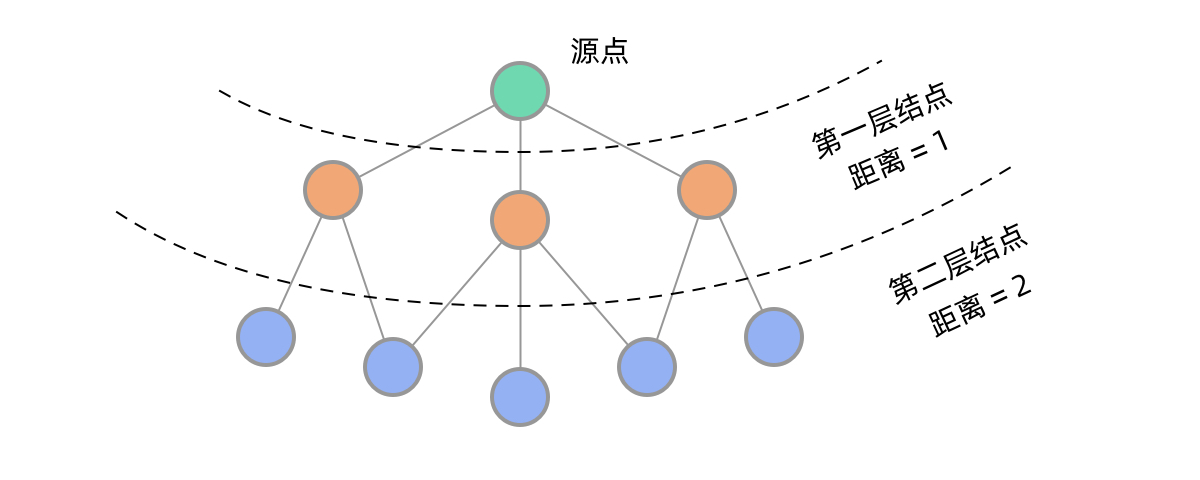
在二叉树中,BFS 可以实现一层一层的遍历。在图中同样如此。从源点出发,BFS 首先遍历到第一层结点,到源点的距离为 1,然后遍历到第二层结点,到源点的距离为 2…… 可以看到,用 BFS 的话,距离源点更近的点会先被遍历到,这样就能找到到某个点的最短路径了。
要解最短路径问题,我们首先要写出层序遍历的代码,仿照上面的二叉树层序遍历代码,类似地可以写出网格层序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void bfs (int [][] grid, int i, int j) Queue<int []> queue = new ArrayDeque<>(); queue.add(new int []{r, c}); while (!queue.isEmpty()) { int n = queue.size(); for (int i = 0 ; i < n; i++) { int [] node = queue.poll(); int r = node[0 ]; int c = node[1 ]; if (r-1 >= 0 && grid[r-1 ][c] == 0 ) { grid[r-1 ][c] = 2 ; queue.add(new int []{r-1 , c}); } if (r+1 < N && grid[r+1 ][c] == 0 ) { grid[r+1 ][c] = 2 ; queue.add(new int []{r+1 , c}); } if (c-1 >= 0 && grid[r][c-1 ] == 0 ) { grid[r][c-1 ] = 2 ; queue.add(new int []{r, c-1 }); } if (c+1 < N && grid[r][c+1 ] == 0 ) { grid[r][c+1 ] = 2 ; queue.add(new int []{r, c+1 }); } } } }
以上的层序遍历代码有几个注意点:
队列中的元素类型是 int[] 数组,每个数组的长度为 2,包含格子的行坐标和列坐标。
1 2 3 int [][] moves = { {-1 , 0 }, {1 , 0 }, {0 , -1 }, {0 , 1 }, };
然后把四个 if 判断变成一个循环:
1 2 3 4 5 6 7 8 for (int [][] move : moves) { int r2 = r + move[0 ]; int c2 = c + move[1 ]; if (inArea(grid, r2, c2) && grid[r2][c2] == 0 ) { grid[r2][c2] = 2 ; queue.add(new int []{r2, c2}); } }
写好了层序遍历的代码,接下来我们看看如何来解决本题中的最短路径问题。
这道题要找的是距离陆地最远的海洋格子。假设网格中只有一个陆地格子,我们可以从这个陆地格子出发做层序遍历,直到所有格子都遍历完。最终遍历了几层,海洋格子的最远距离就是几。
那么有多个陆地格子的时候怎么办呢?一种方法是将每个陆地格子都作为起点做一次层序遍历,但是这样的时间开销太大。
BFS 完全可以以多个格子同时作为起点。我们可以把所有的陆地格子同时放入初始队列,然后开始层序遍历,这样遍历的效果如下图所示:
这种遍历方法实际上叫做「多源 BFS」。多源 BFS 的定义不是今天讨论的重点,你只需要记住多源 BFS 很方便,只需要把多个源点同时放入初始队列即可。
需要注意的是,虽然上面的图示用 1、2、3、4 表示层序遍历的层数,但是在代码中,我们不需要给每个遍历到的格子标记层数,只需要用一个 distance 变量记录当前的遍历的层数(也就是到陆地格子的距离)即可。
最终,我们得到的题解代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 public int maxDistance (int [][] grid) int N = grid.length; Queue<int []> queue = new ArrayDeque<>(); for (int i = 0 ; i < N; i++) { for (int j = 0 ; j < N; j++) { if (grid[i][j] == 1 ) { queue.add(new int []{i, j}); } } } if (queue.isEmpty() || queue.size() == N * N) { return -1 ; } int [][] moves = { {-1 , 0 }, {1 , 0 }, {0 , -1 }, {0 , 1 }, }; int distance = -1 ; while (!queue.isEmpty()) { distance++; int n = queue.size(); for (int i = 0 ; i < n; i++) { int [] node = queue.poll(); int r = node[0 ]; int c = node[1 ]; for (int [] move : moves) { int r2 = r + move[0 ]; int c2 = c + move[1 ]; if (inArea(grid, r2, c2) && grid[r2][c2] == 0 ) { grid[r2][c2] = 2 ; queue.add(new int []{r2, c2}); } } } } return distance; } boolean inArea (int [][] grid, int r, int c) return 0 <= r && r < grid.length && 0 <= c && c < grid[0 ].length; }