Action Recognition(行为识别)
也可以叫 Action Classification
任务目的
给一个视频片段进行分类,类别通常是各类人的动作
任务特点
简化了问题,一般使用的数据库都先将动作分割好了,一个视频片断中包含一段明确的动作,时间较短(几秒钟)且有唯一确定的label。所以也可以看作是输入为视频,输出为动作标签的多分类问题。此外,动作识别数据库中的动作一般都比较明确,周围的干扰也相对较少(不那么real-world)。有点像图像分析中的Image Classification任务。
难点/关键点
- 强有力的特征:即如何在视频中提取出能更好的描述视频判断的特征。特征越强,模型的效果通常较好。
- 特征的编码(encode)/融合(fusion):这一部分包括两个方面,第一个方面是非时序的,在使用多种特征的时候如何编码/融合这些特征以获得更好的效果;另外一个方面是时序上的,由于视频很重要的一个特性就是其时序信息,一些动作看单帧的图像是无法判断的,只能通过时序上的变化判断,所以需要将时序上的特征进行编码或者融合,获得对于视频整体的描述。
- 算法速度:虽然在发论文刷数据库的时候算法的速度并不是第一位的。但高效的算法更有可能应用到实际场景中去。
数据集
行为识别的数据库比较多,这里主要介绍两个最常用的数据库,也是近年这个方向的论文必做的数据库。
- UCF101:来源为YouTube视频,共计101类动作,13320段视频。共有5个大类的动作:1)人-物交互;2)肢体运动;3)人-人交互;4)弹奏乐器;5)运动。数据库主页为:UCF101。文章的题图为UCF各类视频的示意图。
- HMDB51:来源为YouTube视频,共计51类动作,约7000段视频。数据库主页为:HMDB51
在Actioin Recognition中,实际上还有一类骨架数据库,比如MSR Action 3D,HDM05,SBU Kinect Interaction Dataset等。这些数据库已经提取了每帧视频中人的骨架信息,基于骨架信息判断运动类型。不做详细介绍
方法

Temporal Action Proposals(时间行动建议)
任务目的
Temporal Action Proposal任务不需要对活动分类,只需要找出proposals,主要目的是将长视频根据语义分割成多个segment。所以判断找的temporal proposals全不全就可以测评方法好坏,常用average recall (AR) ,Average Recall vs. Average Number of Proposals per Video (AR-AN) 即曲线下的面积(ActivityNet Challenge 2017就用这个测评此项任务)。如下图:

任务特点
为了适应视频数据集的特点,好的action proposal应该具有如下的特点:
- 能够高效地表示一个视频间隔(temporal segment),计算开销小。
- 将可能具有action的视频间隔(temporal segment)找出来。
- 初步识别出视频间隔中的动作是否为我们感兴趣的动作类别之一。
数据集
目前使用比较广泛的数据集为ActivityNet-1.3(2016年发布)以及早些年的一个相对较小的数据集THUMOS14。
THUMOS14是一个包含action recognition和action localization任务的比赛,其中训练集是trimmed UCF101,所以训练集不能被用来训练action proposal网络。验证集集有1010个视频,测试集有1574个视频。但是验证集中只有200个视频有temporal label,测试集中只有212个。一般情况下,大家使用验证集来训练action proposal网络,然后在测试集上查看效果。
用于训练的验证集上每个类别平均有150个动作时序标注,每个动作平均的持续时间为4.04秒。一共有3007个动作时序标注,标注了的动作共持续12159.8秒。测试集上的每个类别平均有167.9个动作时序标注,每个动作平均的持续时间为4.47秒,标注了的动作共持续15040。3秒。验证集上不同类别的标注个数及平均动作持续时间如下图

ActivityNet-1.3共有200个类别,训练集有10024个视频,验证集有4926个视频,测试集有5044个视频。官方提供的视频分辨率为320x240,除了视频之外还提供了按照5FPS 使用的代码,以及使用ResNet-152在抽好的帧上提取的feature。一般来说对于Action Proposal需要在提供的帧上进行实验,或者为了更好地利用标注也可以自己进行密集抽帧。
就标注来看,共有23065个动作时序标注,平均每个视频有1.15个时序标注。视频的平均时长为128秒,标注的平均时长为49.2秒。
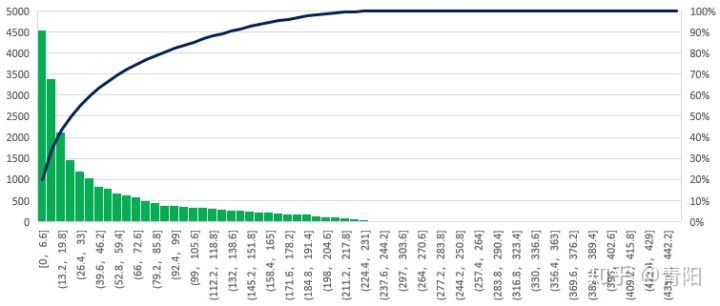 时序动作标注长度分布图
时序动作标注长度分布图
就类别分布来看,平均每个类别有115个标注,平均每个类别的动作持续时间为51.3秒。
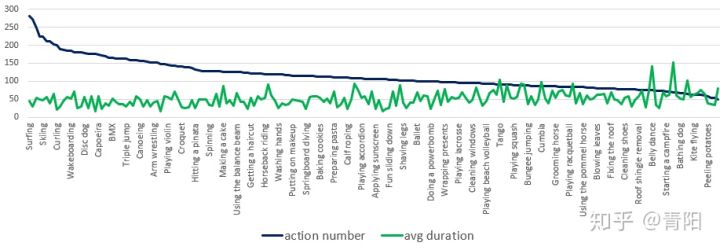 类别动作持续时间图
类别动作持续时间图

ActivityNet 任务的提交格式
Temporal Action Localization (时序动作定位)
也可以叫 Temporal Action Detection (时序行为检测)
任务目的
给定一段未分割的长视频,算法需要检测视频中的行为片段(action instance),包括其开始时间、结束时间以及类别。一段视频中可能包含一个或多个行为片段。
(1) temporal action proposal generation: 即进行时序动作提名,产生候选的视频时序片段,即相当于Faster-RCNN中的RPN网络的作用;
(2) action classification: 即判断候选视频时序片段的动作类别。两个部分结合在一起,即实现了视频中的时序动作检测。目前视频分类算法的精度其实以及比较高了,然而时序检测的效果依旧比较低,主要的性能瓶颈在于时序提名环节。
任务特点
特点1
action recognition与temporal action detection之间的关系同 image classfication与 object detection之间的关系非常像。基于image classification问题,发展出了许多强大的网络模型(比如ResNet,VGGNet等),这些模型在object detection的方法中起到了很大的作用。同样,action recognition的相关模型(如2stream,C3D, iDT等)也被广泛的用在temporal action detection的方法中。
特点2
由于temporal action detection和object detection之间存在一定的相似性,所以很多temporal action detection方法都采用了与一些object detection方法相似的框架(最常见的就是参考R-CNN系列方法)。具体的会在后面的论文介绍中讲到。
难点/关键点
难点1
在目标检测中,物体目标的边界通常都是非常明确的,所以可以标注出较为明确的边界框。但时序行为的边界很多时候并不是很明确,什么时候一个行为算开始,什么时候行为算结束常常无法给出一个准确的边界(指精确的第几帧)。
难点2
只使用静态图像的信息,而不结合时序信息在行为识别中是可以的(虽然结合时序信息效果会更好)。但在时序行为检测中,是无法只使用静态图像信息的。必须结合时序的信息,比如使用RNN读入每帧图像上用CNN提取的特征,或是用时序卷积等。
难点3
时序行为片段的时间跨度变化可能非常大。比如在ActivityNet中,最短的行为片段大概1s左右,最长的行为片段则超过了200s。巨大的时长跨度,也使得检测时序动作非常难。
任务关键点
我认为设计一个好的时序行为检测方法的关键主要在于以下两点:
高质量的时序片段(Proposals):很多方法都是使用Proposal + classification的框架。对于这类方法,重要的是较高的proposal质量(即在保证平均召回率的情况下,尽可能减少proposal的数量)。此外,对于所有方法,获取准确的时序行为边界都是非常重要的。
准确的分类(Classification):即能准确的得到时序行为片段的类别信息。这里通常都会使用行为识别中的一些方法与模型。
数据集
时序行为检测的数据库也有很多,下面主要介绍几个常用的主流数据库:
- THUMOS 2014:该数据集即为THUMOS Challenge 2014,地址为THUMOS 2014。该数据集包括行为识别和时序行为检测两个任务。它的训练集为UCF101数据集,包括101类动作,共计13320段分割好的视频片段。THUMOS2014的验证集和测试集则分别包括1010和1574个未分割过的视频。在时序行为检测任务中,只有20类动作的未分割视频是有时序行为片段标注的,包括200个验证集视频(包含3007个行为片段)和213个测试集视频(包含3358个行为片段)。这些经过标注的未分割视频可以被用于训练和测试时序行为检测模型。实际上之后还有THUMOS Challenge 2015,包括更多的动作类别和视频数,但由于上面可以比较的方法不是很多,所以目前看到的文章基本上还是在THUMOS14上进行实验。
- MEXaction2:MEXaction2数据集中包含两类动作:骑马和斗牛。该数据集由三个部分组成:YouTube视频,UCF101中的骑马视频以及INA视频,数据集地址为MEXaction2 。其中YouTube视频片段和UCF101中的骑马视频是分割好的短视频片段,被用于训练集。而INA视频为多段长的未分割的视频,时长共计77小时,且被分为训练,验证和测试集三部分。训练集中共有1336个行为片段,验证集中有310个行为片段,测试集中有329个行为片断。且MEXaction2数据集的特点是其中的未分割视频长度都非常长,被标注的行为片段仅占视频总长的很低比例
- ActivityNet: 目前最大的数据库,同样包含分类和检测两个任务。数据集地址为Activity Net ,这个数据集仅提供视频的youtube链接,而不能直接下载视频,所以还需要用python中的youtube下载工具来自动下载。该数据集包含200个动作类别,20000(训练+验证+测试集)左右的视频,视频时长共计约700小时。由于这个数据集实在太大了,我的实验条件下很难完成对其的实验,所以我之前主要还是在THUMOS14和MEXaction2上进行实验。

ActivityNet 任务的提交格式
方法

Temporal Action Parsing (TAP) (时态动作解析)
相关论文《Intra- and Inter-Action Understanding via Temporal Action Parsing》
相关数据集Datasets
- only class labels:
- KTH, Weizmann, UCFSports, Olympic
- UCF101, HMDB51, Sports1M, Kinetics
- boundaries of actions in untrimmed video:
- THUMOS’15, ActivityNet, Charades, HACS, AVA
- finegrained annotations for action instances(author’s): 动作实例的细粒度注释
- Salads, Breakfast, MPIICooking, JIGSAWS
为2020年CVPR 商汤等新提出的任务,在一段动作视频中,定义一连串子动作(sub-action),动作解析即定位这些子动作的开始帧。该任务可更好的进行动作间和动作内部的视频理解。
任务
- 对动作实例的内部结构的详细了解,特别是在时间维度上(TAP/TAS)
- TAP仅提供了子动作之间的边界,而这些边界的监督作用却明显较弱
- TAS的目标是在一组预定义的子动作中标记动作实例的每一个框架,这些子动作可以在一个监督下完成
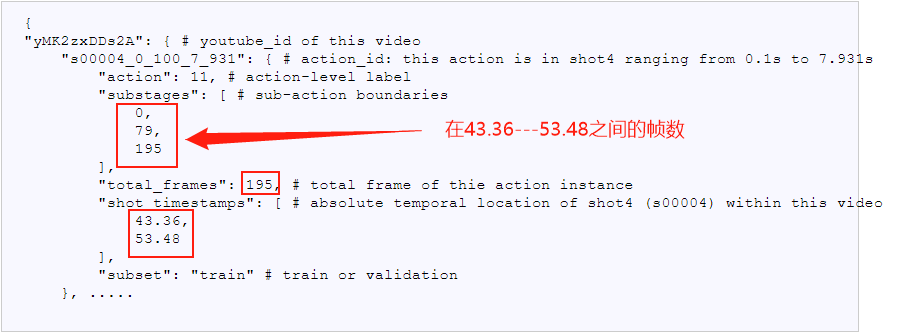

特点: 每个未剪辑的视频类别是一样的,子动作的边界给出,但是没有给出子动作的类比
Baseline

动作边界检测。我们借助于序列模型,特别是时间卷积网络(TCN),来估计动作状态变化的出现。给定一个T帧片段,在顶部构建一个两层时间卷积网络来密集预测每个帧的标量。接下来,带注释的时间边界及其k个相邻帧被标记为1,其余的被设置为0。由于正样本(即子动作变化点)和负样本之间的不平衡,使用加权二进制交叉熵损失来优化网络。在推断期间,一旦输出超过某个阈值θc,例如0.5,就检测到子动作。
 \
\
弱监督时间动作分割。时间动作分割旨在用一组预定义的子动作来标记动作实例的每个帧。在弱监督设置中,仅提供按发生顺序排列的子动作列表,而没有精确的时间位置。我们通过迭代软边界分配(ISBA) [6]和连接主义时间建模(CTM) [18]选择了两个有代表性的方法。对于ISBA,我们通过提取帧级特征{ fi } N i = 1并将它们预分组为K个簇来生成伪标签。对CTM来说,最初的训练目标是最大化预定义目标标记的对数似然性。在我们的例子中,损失被改变为所有可能标签的对数似然的和,因为所有k个有区别的随机抽样子动作可能是一个可能的解决方案。在推断过程中,我们使用简单的最佳路径解码,即在每个时间戳连接最活跃的输出。
评测

输出的是每个子动作的开始帧 用于评测的是召回率,精确率,f1分数