Java内存模型(JMM)
JVM内存模型指的是JVM的内存分区;而java内存模型是一种虚拟机规范
JMM就是Java内存模型(Java Mermory Model)。因为在不同的硬件生产商和不同的操作系统下,内存的访问有一定的差异,所以会造成相同的代码运行在不同的系统上会出现各种问题。所以Java内存模型(JMM)屏蔽掉各种硬件和和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果
Java内存模型规定所有的变量存储在主内存中,包括 实例变量,静态变量,但是不包括局部变量和方法参数,每个线程都有自己的工作内存,线程的工作内存保存了该线程用的到变量和主内存的副本拷贝,线程对变量的操作 都在工作内存中进行。线程不能直接读写主内存中的变量。
不同的线程之间也无法访问对方工作内存中的变量,线程之间变量值的传递均需要通过主内存来完成
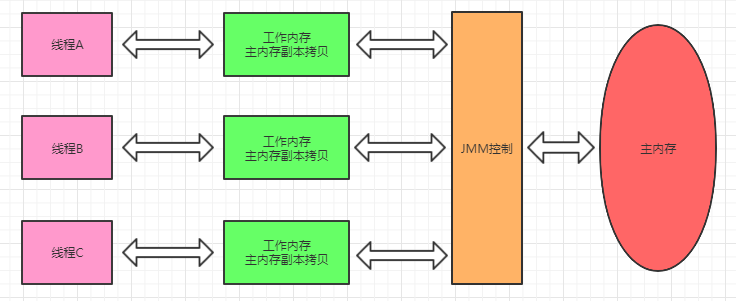
每个线程的工作内存都是独立的,线程操作数据只能在工作内存中进行,然后刷会主存,这是JMM的线程基本工作方式
JMM定义了什么
整个Java内存模型实际上是围绕着三个特征建立起来的。分别是:原子性(Atomicity),可见性(Visibility),有序性(Ordering)。这三个特征可谓是整个Java并发的基础
原子性
原子性指的是一个操作是不可分割,不可中断的,一个线程在执行时不会被其他线程干扰。
1 | int i = 2; |
第一句是基本类型赋值操作,必定是原子性操作。
第二句先读取i的值,再赋值到j,两步操作,不能保证原子性。
第三和第四句其实是等效的,先读取i的值,再+1,最后赋值到i,三步操作了,不能保证原子性。
JMM只能保证基本的原子性,如果要保证一个代码块的原子性,提供了monitorenter 和 moniterexit 两个字节码指令,也就是 synchronized 关键字。因此在 synchronized 块之间的操作都是原子性的。
可见性
可见性指当一个线程修改共享变量的值,其他线程能够立即知道被修改了。Java是利用Volatile关键字来提供可见性的。当变量被volatile修饰时,这个变量被修改后会立即刷新到主内存,当其他线程需要读取该变量时,会去至内存中读取新值。而普通变量则不能保证这一点
除了volatile关键字之外,final和synchronized也能实现可见性。
synchronized的原理是,在执行完,进入unlock之前,必须将共享变量同步到主内存中。
final修饰的字段,一旦初始化完成,如果没有对象逸出(指对象为初始化完成就可以被别的线程使用),那么对于其他线程都是可见的。
有序性
在Java中,可以使用synchronized或者volatile保证多线程之间操作的有序性。实现原理有些区别:
volatile关键字是使用内存屏障达到禁止指令重排序,以保证有序性。
synchronized的原理是,一个线程lock之后,必须unlock后,其他线程才可以重新lock,使得被synchronized包住的代码块在多线程之间是串行执行的。
八种内存交互操作
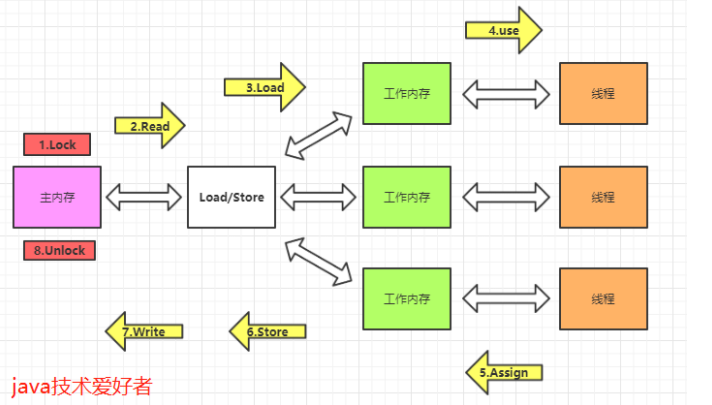
- lock(锁定),作用于主内存中的变量,把变量标识为线程独占的状态。
- read(读取),作用于主内存的变量,把变量的值从主内存传输到线程的工作内存中,以便下一步的load操作使用。
- load(加载),作用于工作内存的变量,把read操作主存的变量放入到工作内存的变量副本中。
- use(使用),作用于工作内存的变量,把工作内存中的变量传输到执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
- assign(赋值),作用于工作内存的变量,它把一个从执行引擎中接受到的值赋值给工作内存的变量副本中,每当虚拟机遇到一个给变量赋值的字节码指令时将会执行这个操作。
- store(存储),作用于工作内存的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用。
- write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
- unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
再补充一下JMM对8种内存交互操作制定的规则吧:
- 不允许read、load、store、write操作之一单独出现,也就是read操作后必须load,store操作后必须write。
- 不允许线程丢弃他最近的assign操作,即工作内存中的变量数据改变了之后,必须告知主存。
- 不允许线程将没有assign的数据从工作内存同步到主内存。
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过load和assign操作。
- 一个变量同一时间只能有一个线程对其进行lock操作。多次lock之后,必须执行相同次数unlock才可以解锁。
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值。在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值。
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量。
- 一个线程对一个变量进行unlock操作之前,必须先把此变量同步回主内存。
volatile关键字
- 保证线程间变量的可见性
- 禁止CPU进行指令重排
可见性
volatile修饰的变量,当一个线程改变了该变量的值,其他线程是立即可见的。普通变量则需要重新读取才能获得最新值。
volatile保证可见性的流程大概就是这个一个过程:
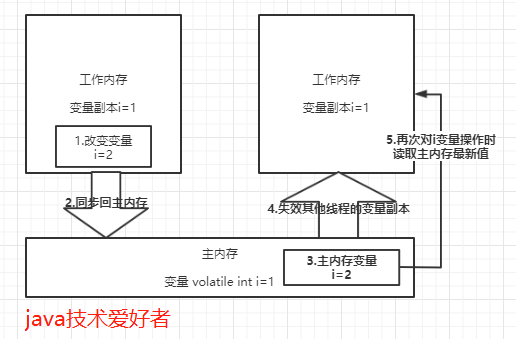
volatile一定能保证线程安全吗
先说结论吧,volatile不能一定能保证线程安全。
怎么证明呢,我们看下面一段代码的运行结果就知道了:
1 | /** |
为什么volatile不能保证线程安全?
很简单呀,可见性不能保证操作的原子性,前面说过了count++不是原子性操作,会当做三步,先读取count的值,然后+1,最后赋值回去count变量。需要保证线程安全的话,需要使用synchronized关键字或者lock锁,给count++这段代码上锁:
1 | private static synchronized void add() { |
禁止指令重排序
首先要讲一下as-if-serial语义,不管怎么重排序,(单线程)程序的执行结果不能被改变。
为了使指令更加符合CPU的执行特性,最大限度的发挥机器的性能,提高程序的执行效率,只要程序的最终结果与它顺序化情况的结果相等,那么指令的执行顺序可以与代码逻辑顺序不一致,这个过程就叫做指令的重排序。
重排序的种类分为三种,分别是:编译器重排序,指令级并行的重排序,内存系统重排序。整个过程如下所示:

指令重排序在单线程是没有问题的,不会影响执行结果,而且还提高了性能。但是在多线程的环境下就不能保证一定不会影响执行结果了。
所以在多线程环境下,就需要禁止指令重排序。
volatile关键字禁止指令重排序有两层意思:
- 当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见,在其后面的操作肯定还没有进行。
- 在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
下面举个例子:
1 | private static int a;//非volatile修饰变量 |
变量a,b是非volatile修饰的变量,k则使用volatile修饰。所以语句3不能放在语句1、2前,也不能放在语句4、5后。但是语句1、2的顺序是不能保证的,同理,语句4、5也不能保证顺序。
并且,执行到语句3的时候,语句1,2是肯定执行完毕的,而且语句1,2的执行结果对于语句3,4,5是可见的。
volatile禁止指令重排序的原理是什么
首先要讲一下内存屏障,内存屏障可以分为以下几类:
- LoadLoad 屏障:对于这样的语句Load1,LoadLoad,Load2。在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- StoreStore屏障:对于这样的语句Store1, StoreStore, Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
- LoadStore 屏障:对于这样的语句Load1, LoadStore,Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreLoad 屏障:对于这样的语句Store1, StoreLoad,Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
在每个volatile读操作后插入LoadLoad屏障,在读操作后插入LoadStore屏障。
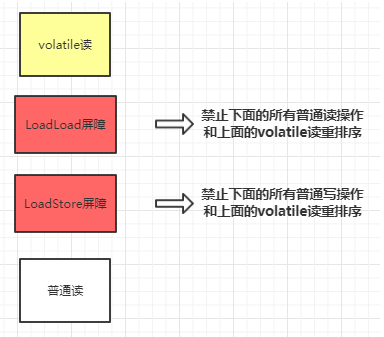
在每个volatile写操作的前面插入一个StoreStore屏障,后面插入一个SotreLoad屏障。
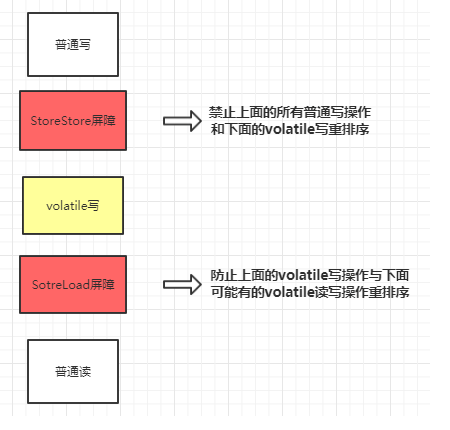
大概的原理就是这样。








