1 | update t set b = 200 where id = 2 |
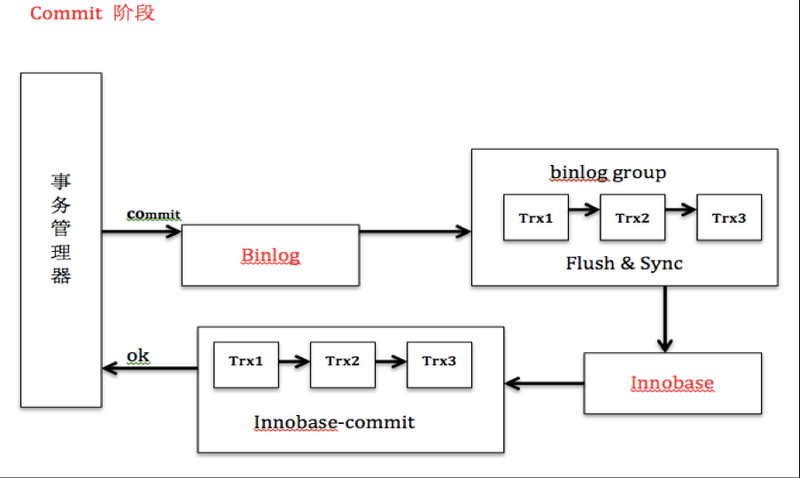
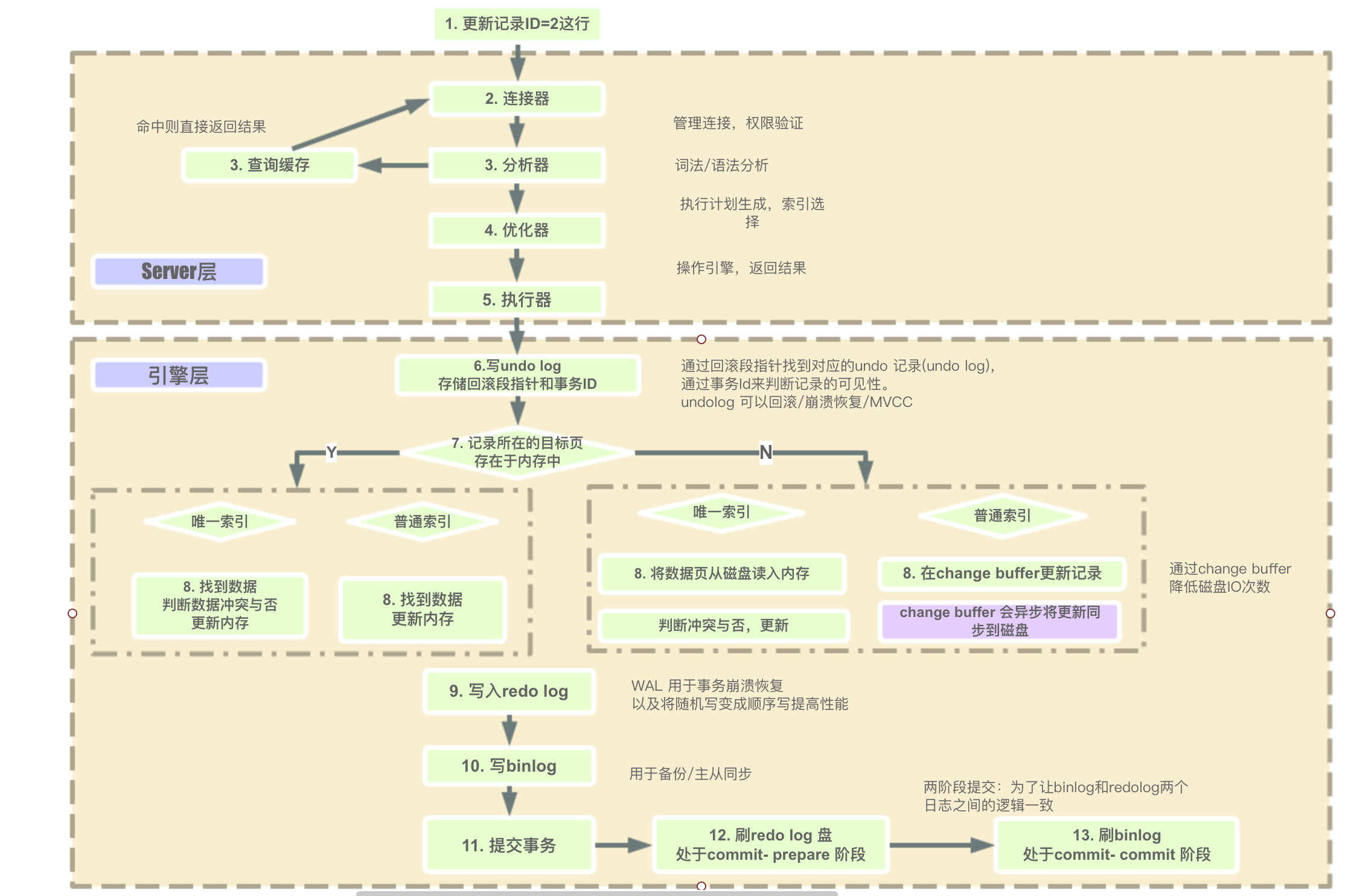
语句的执行过程如下:
- 客户端(通常是你的服务)发出更新语句” update t set b = 200 where id = 2 “ 并向MySQL服务端建立连接;
- MySQL连接器负责和客户端建立连接,获取权限,维持和管理连接;
- MySQL拿到一个查询请求后,会先到查询缓存看看(MySQL8.x已经废弃了查询缓存),看之前是否已经执行过,如果执行过,执行语句及结果会以key-value形式存储到内存中,如果命中缓存会返回结果。如果没命中缓存,就开始真正执行语句。分析器会先做词法分析,识别出关键字update,表名等等;之后还会做语法分析,判断输入的语句是否符合MySQL语法;
- 经过分析器,MySQL已经知道语句是要做什么。优化器接着会选择使用哪个索引(如果多个表,会选择表的连接顺序);
- MySQL服务端最后一个阶段是执行器会调用引擎的接口去执行语句;
- 事务开始(任何一个操作都是事务),写undo log ,记录记录上一个版本数据,并更新记录的回滚指针和事务ID;
- 执行器先调用引擎取id=2这一行。id是主键,引擎直接用树搜索找到这一行;
- 如果id=2这一行所在的数据页本来就在内存 中,就直接返回给执行器更新;
- 如果记录不在内存,接下来会判断索引是否是唯一索引;
- 如果不是唯一索引,InnoDB会将更新操作缓存在change buffer中;
- 如果是唯一索引,就只能将数据页从磁盘读入到内存,返回给执行;
- 执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在就是N+1,得到新的一行数据,再调用引擎接口写入这行新数据;
- 引擎将这行数据更新到内存中,同时将这个更新操作记录到redo log 里面;
- 执行器生成这个操作的binlogbinlog ;
- 执行器调用引擎的提交事务接口;
- 事务的两阶段提交:commit的prepare阶段:引擎把刚刚写入的redo log刷盘;
- 事务的两阶段提交:commit的commit阶段:引擎binlog刷盘。
[ ](https://gsmtoday.github.io/2019/02/08/how-update-executes-in-mysql/update process.png)
](https://gsmtoday.github.io/2019/02/08/how-update-executes-in-mysql/update process.png)
MySQL基本架构
MySQL可以分为Server层和存储引擎层两部分。
Server层包括连接器、查询缓存、分析器、优化器、执行器。涵盖MySQL的大多数核心服务功能,以及所有的内置函数(日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层负责数据的存储和提取。其架构是插件式的,支持InnoDB,MyISAM,Memory等多个存储引擎。现在最常用的存储引擎是InnoDB, 它从MySQL5.5.5开始成为了默认存储引擎。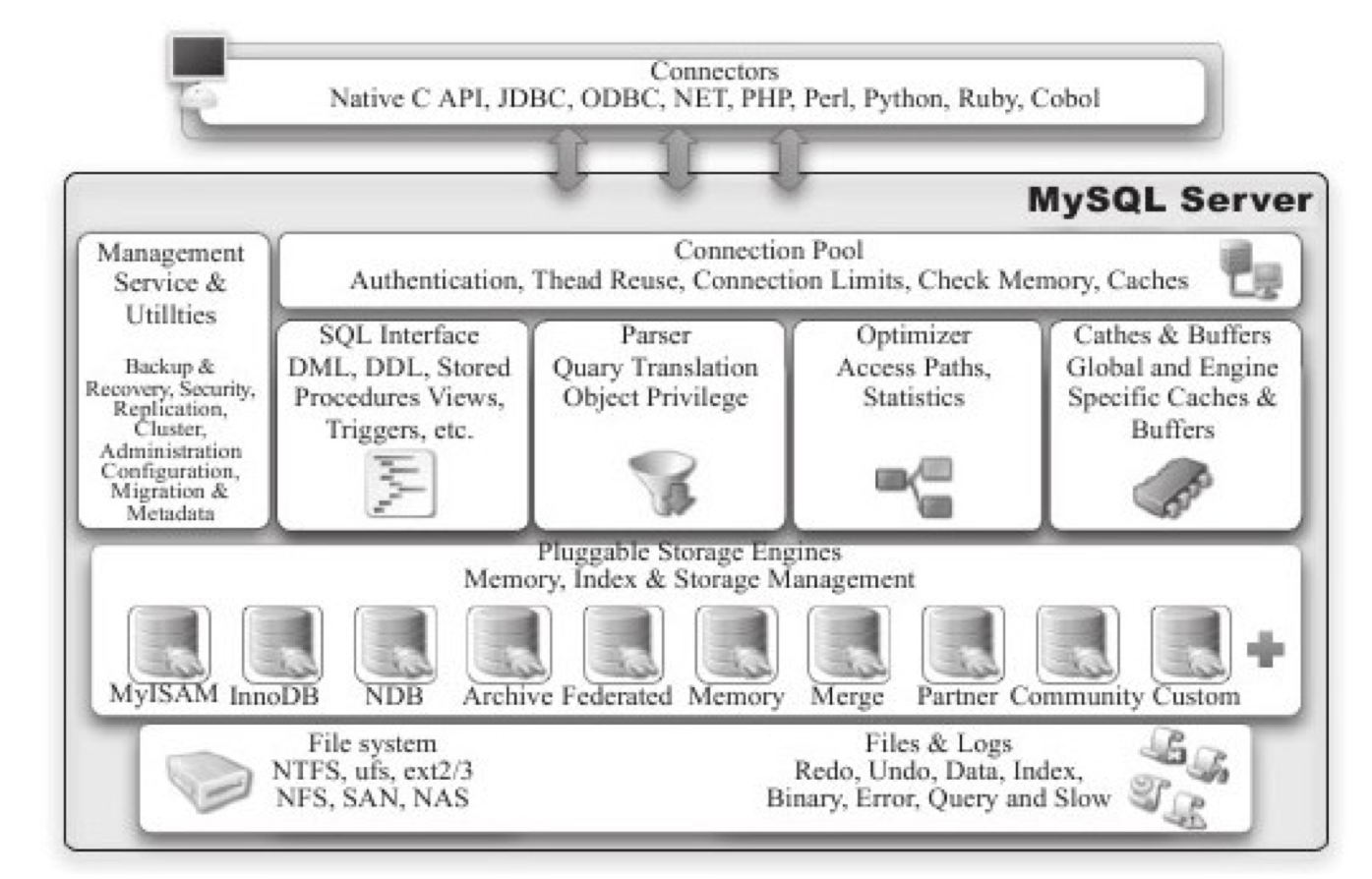
Undo log 简述
【概述】Undo log 是InnoDB MVCC事务特性的重要组成部分。当我们对记录做了变更操作时就会产生undo记录,undo记录默认被记录到系统表ibdata中,但是从MySQL 5.6以后 也可以使用独立的Undo 表空间。
【作用】其作用是保存记录的老版本数据,当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着undo链找到满足其可见性的记录。当版本链很长时,通常可以认为是个比较耗时的耗时操作。因此可以用来回滚,崩溃恢复,MVCC。
大多数对数据的变更操作包括INSERT/DELETE/UPDATE,其中INSERT操作在事务提交前只对当前事务可见,因此产生的Undo日志可以在事务提交后直接删除,而对于UPDATE/DELETE则需要维护多版本信息,在InnoDB里,UPDATE和DELETE操作产生的Undo日志被归成一类,即update_undo。
【产生时机】事务开始之前,将当前的数据版本生成Undo log, Undo log也会产生redo log 来保证Undo log的可靠性。
【释放时机】当事务提交后,Undo log并不能立马被删除,而是放入待清理的链表,由purge 线程判断是否由其他事务在使用undo 段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间。
【存储结构】InnoDB采用回滚段的方式来维护Undo log的并发写入和持久化。
回滚段实际上是一种Undo 文件组织方式,Undo内部由多个回滚段组成,即 Rollback segment,一共有128个,保存在ibdata系统表空间中,分别从resg slot0 - resg slot127,每一个resg slot,也就是每一个回滚段,内部由1024个undo segment 组成。
为了便于管理和使用undo记录,在内存中维持了如下关键结构体对象:
1.所有回滚段都记录在 trx_sys->rseg_array,数组大小为128,分别对应不同的回滚段;
2.rseg_array 数组类型为trx_rseg_t,用于维护回滚段相关信息;
3.每个回滚段对象trx_rseg_t 还要管理undo log信息,对应结构体为trx_undo_t, 使用多个链表来维护trx_undo_t信息;
4.事务开启时,会专门给他指定一个回滚段,以后该事务用到的undo log页,就从该回滚段上分配;
5.事务提交后,需要purge的回滚段会被放到purge队列上(purge_sys->purge_queue)。
Change Buffer简述
1 | 当需要更新一个数据页: |
另外,虽然叫change buffer, 实际上此操作也是可以持久化的数据。将change buffer中的操作应用到原始数据页,得到最新结果的过程叫merge。除了访问这个数据页会触发merge 外,系统有后台线程会定期merge. 在db正常关闭的时候,也会执行merge。 — 如果能够将更新操作先记录在change buffer,减少读磁盘,更新语句的执行速度会得到明显的提升 。
使用场景
Change buffer的主要目的就是将记录的变更动作缓存下来,所以在一个数据页做purge之前,change buffer 记录的变更越多(也就是这个页面上要更新的次数越多),收益就越大。
因此对于写多读少的业务,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好。这种业务模型常见的是账单类,日志类的系统。
反过来,假设一个业务的更新模式就是写入之后马上会做查询,那么即使满足了条件,将先更新记录在change buffer,但之后由于马上要访问这个数据页,会立即出发purge过程。这样随机访问IO的次数不会减少,反而增加了change buffer的维护代价,所以对于这种业务模式来说,change buffer反而起到了副作用。
另外,只有普通索引才能使用到change buffer, 唯一索引不能用。因为唯一索引每次都要将数据页读入内存判断唯一性,所以没必要使用change buffer了。
Redo log简述
1 | 保证事务的持久性。日志先行(WAL 先写日志,再写磁盘。),即在持久化数据文件前,保证之前的redo 日志已经写在磁盘。记录的是新数据的备份。在事务提交前,只要将Redo Log持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是RedoLog已经持久化。系统可以根据RedoLog的内容,将所有数据恢复到最新的状态。 |
WAL好处:
1.利用WAL技术,数据库将随机写换成了顺序写,大大提升了数据库性能。
2.保证crash safe : 有了redo log 可以保证即使数据库发生异常重启,之前提交的记录都不会丢失。
WAL坏处:
但是也会带来内存脏页问题,内存脏页会后台线程自动flush,也会由于数据页淘汰而触发flush. flush脏页的过程会占用资源,可能导致查询语句的响应时间长一些。
Redo log 特点
InnoDB的redo log是固定大小的,比如可以配置为一组4个文档,每个1GB,从头开始写,写到末尾就又回到开头循环写。redo log通过使用两个指针checkpoint&writepos来控制数据更新到数据文件速度。
另外,redo log是InnoDB引擎特有的日志。
WAL /redo log V.S. change buffer
WAL /redo log 提升性能的核心机制即尽量减少随机写磁盘的IO消耗(转成顺序写)。而Change buffer 的提升性能的核心机制是节省更新语句中随机读磁盘的IO消耗 。
两阶段提交2PC
2PC即Innodb对于事务的两阶段提交机制。当MySQL开启binlog的时候,会存在一个内部XA的问题:事务在存储引擎层(redo)commit的顺序和在binlog中提交的顺序不一致的问题。如果不使用两阶段提交,那么数据库的状态有可能用它的日志恢复出来的库的状态不一致。
事务的commit分为prepare和commit两个阶段:
1、prepare阶段:redo持久化到磁盘(redo group commit),并将回滚段置为prepared状态,此时binlog不做操作。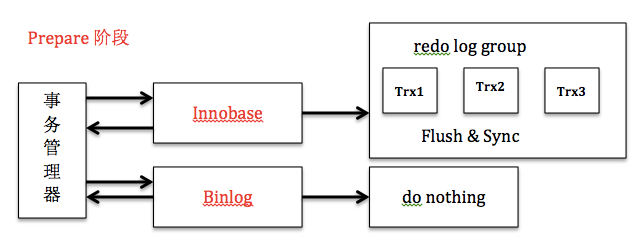
2、commit阶段:innodb释放锁,释放回滚段,设置提交状态,binlog持久化到磁盘,然后存储引擎层提交。