Linux系统之进程状态
- D:uninterruptible sleep (usually IO)
- R:running or runnable (on run queue)
- S:interruptible sleep (waiting for an event to complete)
- T:stopped by job control signal
- t:stopped by debugger during the tracing
- W:paging (not valid since the 2.6.xx kernel)
- X:dead (should never be seen)
- Z:defunct (“zombie”) process, terminated but not - reaped by its parent
1、R (TASK_RUNNING),可执行状态
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进而,进程调度器就从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
很多操作系统教科书将正在CPU上执行的进程定义为RUNNING状态、而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为 TASK_RUNNING状态。
2、S (TASK_INTERRUPTIBLE),可中断的睡眠状态
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构(进程控制块)被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么几个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
3、D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。 例如,在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
4、T/t (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态
T (TASK_STOPPED)状态:向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。 SIGSTOP与SIGKILL信号一样,是非常强制的。不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数。 向进程发送一个SIGCONT信号(kill -18),可以让其从TASK_STOPPED状态恢复到TASK_RUNNING状态;或者kill -9直接尝试杀死。
t (TASK_STOPPED)状态:当进程正在被跟踪时,它处于TASK_TRACED这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb(UNIX及UNIX-like下的调试工具)调试中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于TASK_TRACED状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
对于进程本身来说,TASK_STOPPED和TASK_TRACED状态很类似,都是表示进程暂停下来。 而TASK_TRACED状态相当于在TASK_STOPPED之上多了一层保护,处于TASK_TRACED状态的进程不能响应SIGCONT信号而被唤醒。只能等到调试进程通过ptrace系统调用执行PTRACE_CONT、PTRACE_DETACH等操作(通过ptrace系统调用的参数指定操作),或调试进程退出,被调试的进程才能恢复TASK_RUNNING状态。
5、Z (TASK_DEAD - EXIT_ZOMBIE),退出状态,进程成为僵尸进程
进程在退出的过程中,处于TASK_DEAD状态。在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息(保存在task_struct里)。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。
当父/子进程在不同时间点退出时,就可能会出现Z的细分状态:
- 僵尸状态 一个进程使用 fork 创建子进程,如果子进程退出后父进程没有调用 wait 或 waitpid 获取子进程的状态信息,并将子进程释放掉。那么子进程的进程描述符仍然保存在系统中,仍然占用进程表,此时进程就处于僵尸状态。 子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来“收尸”。出现僵尸状态可能有两种情况: 第一种情况,父进程收到通知还没来得及完成收尸,此时正常; 第二种情况,父进程收尸出现异常,此时,只要父进程不退出,子进程的僵尸状态就一直存在,可以通过杀死父进程或者重启来解决。
- 孤儿状态 父进程退出,相应的一个或多个子进程还在运行,那么那些子进程将处于孤儿状态,成为孤儿进程。这些进程会被托管给别的进程,托管给谁呢?可能是退出进程所在进程组的下一个进程(如果存在的话),或者是1号进程。所以每个进程、每时每刻都有父进程存在。除非它是1号进程。 1号进程,pid为1的进程,又称init进程。 linux系统启动后,第一个被创建的用户态进程就是init进程。它有两项使命: 1、执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙); 2、在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成“收尸”工作; init进程不会被暂停、也不会被杀死(这是由内核来保证的)。它在等待子进程退出的过程中处于TASK_INTERRUPTIBLE状态,“收尸”过程中则处于TASK_RUNNING状态。
6、X (TASK_DEAD - EXIT_DEAD),退出状态,进程即将被销毁
进程在退出过程中也可能不会保留它的task_struct。比如这个进程是多线程程序中被detach过的进程。或者父进程通过设置SIGCHLD信号的handler为SIG_IGN,显式的忽略了SIGCHLD信号。(这是posix的规定,尽管子进程的退出信号可以被设置为SIGCHLD以外的其他信号。) 此时,进程将被置于EXIT_DEAD退出状态,这意味着接下来的代码立即就会将该进程彻底释放。所以EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
操作系统中的进程调度策略
先来先服务调度算法:先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入就绪队列。在进程调度中采用FCFS算法时,则每次调度是从就绪队列中选择一个最先进入该队列的进程,为之分配处理机,使之投入运行。该进程一直运行到完成或发生某事件而阻塞后才放弃处理机。
短作业(进程)优先调度算法:短作业(进程)优先调度算法SJ(P)F,是指对短作业或短进程优先调度的算法。它们可以分别用于作业调度和进程调度。短作业优先(SJF)的调度算法是从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行。而短进程优先(SPF)调度算法则是从就绪队列中选出一个估计运行时间最短的进程,将处理机分配给它,使它立即执行并一直执行到完成,或发生某事件而被阻塞放弃处理机时再重新调度。
高优先权优先调度算法:为了照顾紧迫型作业,使之在进入系统后便获得优先处理,引入了最高优先权优先(FPF)调度算法。此算法常被用于批处理系统中,作为作业调度算法,也作为多种操作系统中的进程调度算法,还可用于实时系统中。当把该算法用于作业调度时,系统将从后备队列中选择若干个优先权最高的作业装入内存。当用于进程调度时,该算法是把处理机分配给就绪队列中优先权最高的进程,这时,又可进一步把该算法分成如下两种。
非抢占式优先权算法:在这种方式下,系统一旦把处理机分配给就绪队列中优先权最高的进程后,该进程便一直执行下去,直至完成;或因发生某事件使该进程放弃处理机时,系统方可再将处理机重新分配给另一优先权最高的进程。这种调度算法主要用于批处理系统中;也可用于某些对实时性要求不严的实时系统中。
抢占式优先权调度算法:在这种方式下,系统同样是把处理机分配给优先权最高的进程,使之执行。但在其执行期间,只要又出现了另一个其优先权更高的进程,进程调度程序就立即停止当前进程(原优先权最高的进程)的执行,重新将处理机分配给新到的优先权最高的进程。因此,在采用这种调度算法时,是每当系统中出现一个新的就绪进程i 时,就将其优先权Pi与正在执行的进程j 的优先权Pj进行比较。如果Pi≤Pj,原进程Pj便继续执行;但如果是Pi>Pj,则立即停止Pj的执行,做进程切换,使i 进程投入执行。显然,这种抢占式的优先权调度算法能更好地满足紧迫作业的要求,故而常用于要求比较严格的实时系统中,以及对性能要求较高的批处理和分时系统中。
容易出现优先级倒置现象:优先级反转是指一个低优先级的任务持有一个被高优先级任务所需要的共享资源。高优先任务由于因资源缺乏而处于受阻状态,一直等到低优先级任务释放资源为止。而低优先级获得的CPU时间少,如果此时有优先级处于两者之间的任务,并且不需要那个共享资源,则该中优先级的任务反而超过这两个任务而获得CPU时间。如果高优先级等待资源时不是阻塞等待,而是忙循环,则可能永远无法获得资源,因为此时低优先级进程无法与高优先级进程争夺CPU时间,从而无法执行,进而无法释放资源,造成的后果就是高优先级任务无法获得资源而继续推进。
优先级反转案例解释:不同优先级线程对共享资源的访问的同步机制。优先级为高和低的线程tall和线程low需要访问共享资源,优先级为中等的线程mid不访问该共享资源。当low正在访问共享资源时,tall等待该共享资源的互斥锁,但是此时low被mid抢先了,导致mid运行tall阻塞。即优先级低的线程mid运行,优先级高的tall被阻塞。
优先级倒置解决方案:
- 设置优先级上限,给临界区一个高优先级,进入临界区的进程都将获得这个高优先级,如果其他试图进入临界区的进程的优先级都低于这个高优先级,那么优先级反转就不会发生。
- 优先级继承,当一个高优先级进程等待一个低优先级进程持有的资源时,低优先级进程将暂时获得高优先级进程的优先级别,在释放共享资源后,低优先级进程回到原来的优先级别。嵌入式系统VxWorks就是采用这种策略
- 第三种方法就是临界区禁止中断,通过禁止中断来保护临界区,采用此种策略的系统只有两种优先级:可抢占优先级和中断禁止优先级。前者为一般进程运行时的优先级,后者为运行于临界区的优先级。火星探路者正是由于在临界区中运行的气象任务被中断发生的通信任务所抢占才导致故障,如果有临界区的禁止中断保护,此一问题也不会发生。
高响应比优先调度算法:在批处理系统中,短作业优先算法是一种比较好的算法,其主要的不足之处是长作业的运行得不到保证。如果我们能为每个作业引入前面所述的动态优先权,并使作业的优先级随着等待时间的增加而以速率a 提高,则长作业在等待一定的时间后,必然有机会分配到处理机。该优先权的变化规律可描述为在利用该算法时,每要进行调度之前,都须先做响应比的计算,这会增加系统开销。
时间片轮转法:在早期的时间片轮转法中,系统将所有的就绪进程按先来先服务的原则排成一个队列,每次调度时,把CPU 分配给队首进程,并令其执行一个时间片。时间片的大小从几ms 到几百ms。当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便据此信号来停止该进程的执行,并将它送往就绪队列的末尾;然后,再把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片。这样就可以保证就绪队列中的所有进程在一给定的时间内均能获得一时间片的处理机执行时间。换言之,系统能在给定的时间内响应所有用户的请求。
多级反馈队列调度算法:前面介绍的各种用作进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程,而且如果并未指明进程的长度,则短进程优先和基于进程长度的抢占式调度算法都将无法使用。而多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。在采用多级反馈队列调度算法的系统。
进程同步的四种方法
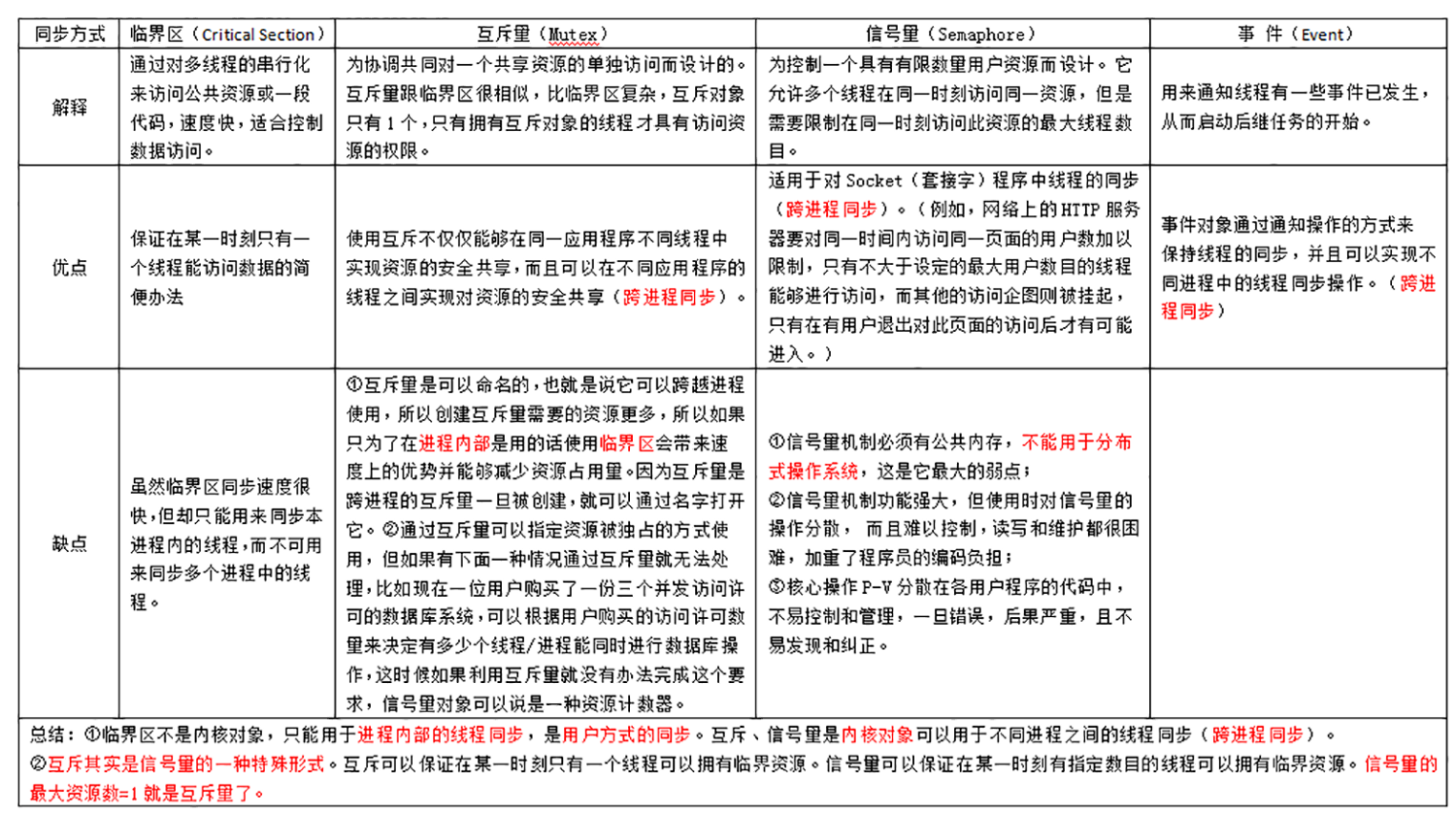
1、临界区(Critical Section):通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。
优点:保证在某一时刻只有一个线程能访问数据的简便办法
缺点:虽然临界区同步速度很快,但却只能用来同步本进程内的线程,而不可用来同步多个进程中的线程。
2、互斥量(Mutex):为协调共同对一个共享资源的单独访问而设计的。
互斥量跟临界区很相似,比临界区复杂,互斥对象只有一个,只有拥有互斥对象的线程才具有访问资源的权限。
优点:使用互斥不仅仅能够在同一应用程序不同线程中实现资源的安全共享,而且可以在不同应用程序的线程之间实现对资源的安全共享。
缺点:①互斥量是可以命名的,也就是说它可以跨越进程使用,所以创建互斥量需要的资源更多,所以如果只为了在进程内部是用的话使用临界区会带来速度上的优势并能够减少资源占用量。因为互斥量是跨进程的互斥量一旦被创建,就可以通过名字打开它。
②通过互斥量可以指定资源被独占的方式使用,但如果有下面一种情况通过互斥量就无法处理,比如现在一位用户购买了一份三个并发访问许可的数据库系统,可以根据用户购买的访问许可数量来决定有多少个线程/进程能同时进行数据库操作,这时候如果利用互斥量就没有办法完成这个要求,信号量对象可以说是一种资源计数器。
3、信号量(Semaphore):为控制一个具有有限数量用户资源而设计。它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目。互斥量是信号量的一种特殊情况,当信号量的最大资源数=1就是互斥量了。
优点:适用于对Socket(套接字)程序中线程的同步。(例如,网络上的HTTP服务器要对同一时间内访问同一页面的用户数加以限制,只有不大于设定的最大用户数目的线程能够进行访问,而其他的访问企图则被挂起,只有在有用户退出对此页面的访问后才有可能进入。)
缺点:①信号量机制必须有公共内存,不能用于分布式操作系统,这是它最大的弱点;
②信号量机制功能强大,但使用时对信号量的操作分散, 而且难以控制,读写和维护都很困难,加重了程序员的编码负担;
③核心操作P-V分散在各用户程序的代码中,不易控制和管理,一旦错误,后果严重,且不易发现和纠正。
4、事件(Event): 用来通知线程有一些事件已发生,从而启动后继任务的开始。
优点:事件对象通过通知操作的方式来保持线程的同步,并且可以实现不同进程中的线程同步操作。
缺点:
总结:
①临界区不是内核对象,只能用于进程内部的线程同步,是用户方式的同步。互斥、信号量是内核对象可以用于不同进程之间的线程同步(跨进程同步)。
②互斥其实是信号量的一种特殊形式。互斥可以保证在某一时刻只有一个线程可以拥有临界资源。信号量可以保证在某一时刻有指定数目的线程可以拥有临界资源。






